
오늘은 주피터노트북의 기본 문법에 대해서 알아보도록 하겠습니다
저두 복습하는겸 찾아가면서 하다보니 조금 재밌더라구요 ㅎㅎ
저의 목표는 어디까지나 바로 학생분들, 직장인분들이 효율적으로 사용할 수 있게 끔 하는거고, 저 또한 그렇게 되는게 목표이기 때문에 바로 실전으로 쓰실 수 있는걸로 가겠습니다.
일단은 실전에 필요한 엑셀 자료 하나 가져오겠습니다.
이 자료는 1978년부터 2017년까지 호주의 실업률을 나이에 따라 분류를 해둔 자료 입니다.
일단은 이 자료로 계속해서 저도 복습을 할거라 저와 같이 하실 분들은 다운해주시고 같이 따라와 주시면 되겠습니다
해당 자료를 저장하실 때에는 꼭 아래로 저장해주셔야 하십니다
c 드라이브 > Users > ' 본인 계정명 ' > PythonDataWorkSpace > ' 본인 지정 폴더'
엑셀 파일 (csv / xlsx) 를 주피터 노트북에서 오픈하기
이 다운받은 엑셀파일을 주피터 노트북에서 한번 오픈을 해봐야 겠죠? 엑셀파일의 오픈은 아래와 같이 진행해주시면 되십니다.

pandas 모듈은 꼭 import 해주셔야 하시구 데이터의 이름을 정해줍시다. 저는 mydata로 지정을 해두었습니다. 그리고 read 명령어를 통해 원하는 엑셀파일을 열어 주시면 되시는 겁니다.
이러고 ctrl + enter를 딱 눌러주시면!
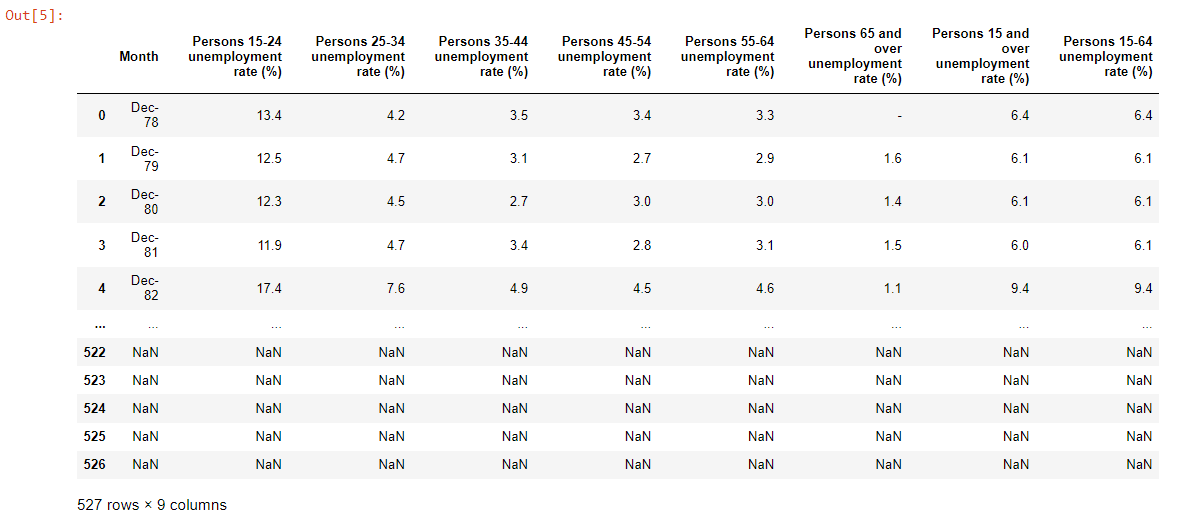
위와 같이 우리가 원하는 데이터가 나오는걸 보실 수 있으십니다 :)
물론 데이터가 너무 많아 좀 이상하게 보이긴 하지만 일단은 그런건 신경쓰지 맙시다
그런데 여기서 Month 옆에 있는 숫자 (0 ~ 526)이 조금 걸리적 거리네요. Month가 Index가 되면 좋겠습니다.

그럼 이렇게 끝에 하나를 더 추가해 줍니다. index column 을 0번째로 지정하겠다 입니다.
주피터노트북도 파이썬과 동일하게 숫자는 0부터 시작합니다. 즉 row에서 첫번째인 month 가 이 데이터의 index 가 되는 겁니다.

이렇게 지정해주시면 우리가 원하는대로 조금 더 깔끔하게 되긴 하였습니다.
원하는 Row의 데이터 가져오기
자 그럼 여기서 이제 원하는 데이터를 가져오는 방법과 간단한 처리 방법들을 보겠습니다.
만약 내가 Persons 15 - 24 unemployment rate, 즉 15 - 24살의 실업률의 데이터만 보고 싶다면 어떻게 해야 할까요?

이렇게 지정해주시면 되십니다. 실행을 하면

이렇게 15 - 24세의 실업률만 보여 줍니다. 미성년자의 실업률도 통계로 내는게 흥미롭네요
간단한 데이터 처리에 대해 알려드리자면
- 해당 데이터의 최소값을 보기 : .min()
- 해당 데이터의 최대값을 보기: .max()
- 해당 데이터의 평균값을 보기: .mean()
이 명령어를 통해 보실 수 있으십니다.

굉장히 간단해 보이지만 각자 업무에서 사용하는 많은량의 데이터가 들어와있는 엑셀을 주피터노트북에 넣어두고, 필요할 때 마다 명령어를 사용해서 바로바로 결과값을 도출해내면 남들보다 조금 더 신속하고 정확하게 업무를 할 수 있지 않을까요?
계속해서 한번 위 데이터를 통해 데이터 처리를 해보도록 하겠습니다.

'Programming > Jupyter Notebook' 카테고리의 다른 글
| 주피터 노트북 (Jupyter Notebook) Column 수정 하기 (데이터 수정) (6) | 2022.07.12 |
|---|---|
| 주피터 노트북 (Jupyter Notebook) 마크다운 알아보기 (1) | 2022.06.14 |
| 주피터 노트북 (Jupyter Notebook) 이란? / 설치방법? - 파이썬을 웹(Web) 으로! (4) | 2022.06.06 |



댓글